MEM1 Learning: Synergizing Memory and Reasoning for Efficient Long-Horizon Agents
Exploring a new approach to memory management in AI agents that maintains constant token length for better efficiency in long-horizon tasks
MEM1 Learning (MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents)
One of the biggest issues with agents is their rather inefficient management of token length. Modern-day agents store all tokens in the process, and as a result, the token length grows linearly. This becomes a big problem when the agent has to work over long horizons with multiple-step objectives. Why would an end user care about this? That’s because it incurs computational costs and takes more time since it has to process all the information at every step. To counter this, the paper proposes a new approach to memory management in agents, one that leads to a constant token length and, at times, results in better inference time than conventional language agents.
This could be something rather complex, given that we are dealing with memory optimization, but the idea behind the suggested framework is rather simple and more human-like. The overall idea is to maintain a constant internal state memory and at every step, to integrate the previous internal state, the query, and any info from an external source into the next step’s internal state, by pruning information the agent deems unnecessary. Something we humans do naturally while conversing, shopping, or researching.
The Problem
Let me help you build a better intuitive understanding of the problem before concluding on a solution using an allegory. Current agentic systems are like people who, every time it’s their turn to talk, remember the entire conversation in detail and process it before answering. As you can imagine, in a short-lived conversation, there is nothing bad about this, but as the conversation length grows, it would be quite inefficient. This long conversation is what the paper refers to as long-horizon problems, which are problems that have up to 16 objective steps.
The issue might be better understood using the following example:
Turn 1: "What is the capital of France?" LLM Process:
1Context = "What is the capital of France?" -> AnswerTurn 2: "What is its population?" LLM Process:
1Context = "What is the capital of France?" + "What is its population?" -> AnswerTurn 3: "Tell me about a famous museum there." LLM Process:
1Context = "What is the capital of France?" + "What is its population?" + "Tell me about a famous museum there." -> AnswerAs you can already tell, this full context is a problem. Three of the major issues with this are:
- With unbounded memory growth, the context window will grow indefinitely.
- Increased computation cost is a rather obvious one; as the context window increases, the LLM has to process it all before answering every time.
- Degraded Reasoning Performance. As the context window grows, the chances of the agent getting “lost” in irrelevant information increase.
Hence, developing an efficient memory management solution becomes vital.
The Proposed Approach
The following is the approach the paper suggests:
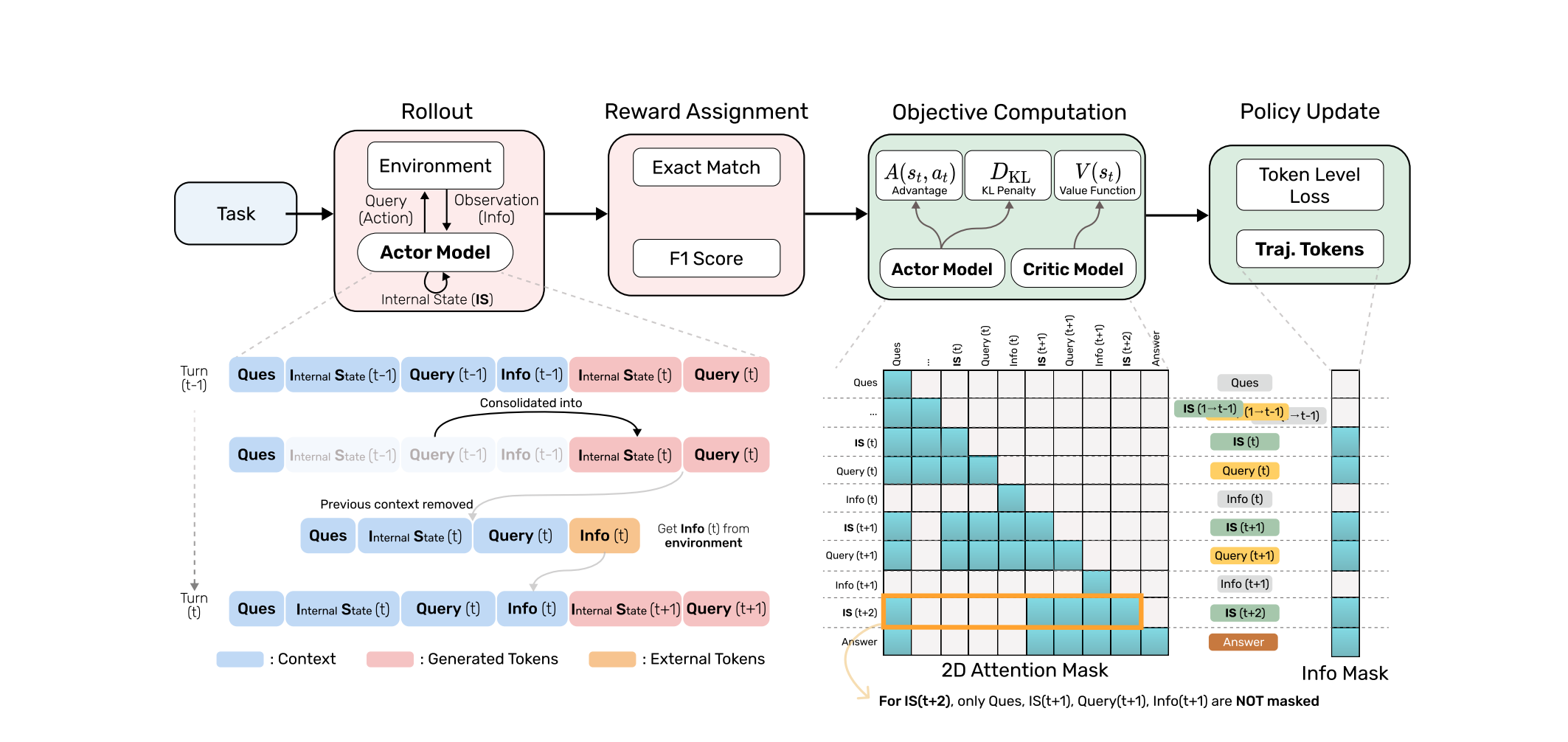
On top is the training pipeline, consisting of the following stages:
- Rollout: This is where the process begins. The agent is provided with a Task, and it then, based on its Internal State (this is its optimized memory), takes an action. In return, the environment provides an observation, based on which the agent updates its internal state. This loop continues until the task is brought to completion.
- Reward Assignment: After the completion of the task, its performance is measured using metrics like "F1 Score" and "Exact Match", serving as reward signals for the agent.
- Objective Computation: In this step, the agent’s policy is refined. The Actor model generates actions, whereas the Critic Model evaluates their effectiveness, helping the agent learn which actions lead to better outcomes.
- Policy Update: The agent’s policy is updated using the computed objective, with the aim of maximizing rewards and minimizing penalties.
The Evolution of the Internal State (bottom Left) is the main difference between MEM1 and other agents; this is the point where better memory management takes place. The Internal State has a sort of Markov property, where at any turn (t), you only need the last turn (t-1) to help determine the current state and not the full history.
At turn (t), the agent performs an action. Instead of keeping all past information, it creates a new consolidated internal state. This new IS contains only the essential information from the previous turn’s context. The previous context is removed, and the agent adds new information (info) from its recent action. The same process repeats for turn (t + 1).
The 2D matrix on the right is called an attention mask. The idea is that the agent can only see the “Non-Masked” parts of the context, which prevents the agent from seeing the answers or future information, ensuring the model learns sequentially. The colored boxes show which pieces of information the model is allowed to attend to, and white squares are the ones that are masked out. The info mask is used to filter out external tokens, basically all the tokens given to the agent by the environment, not something the agent generated itself.
Results

Above is the graph the paper uses to display its results:
The purple line represents the MEM1 exact match score over the number of objectives. The purpose of the EM score is to show accuracy and how correctly the model answered the questions as the number of objectives increased.
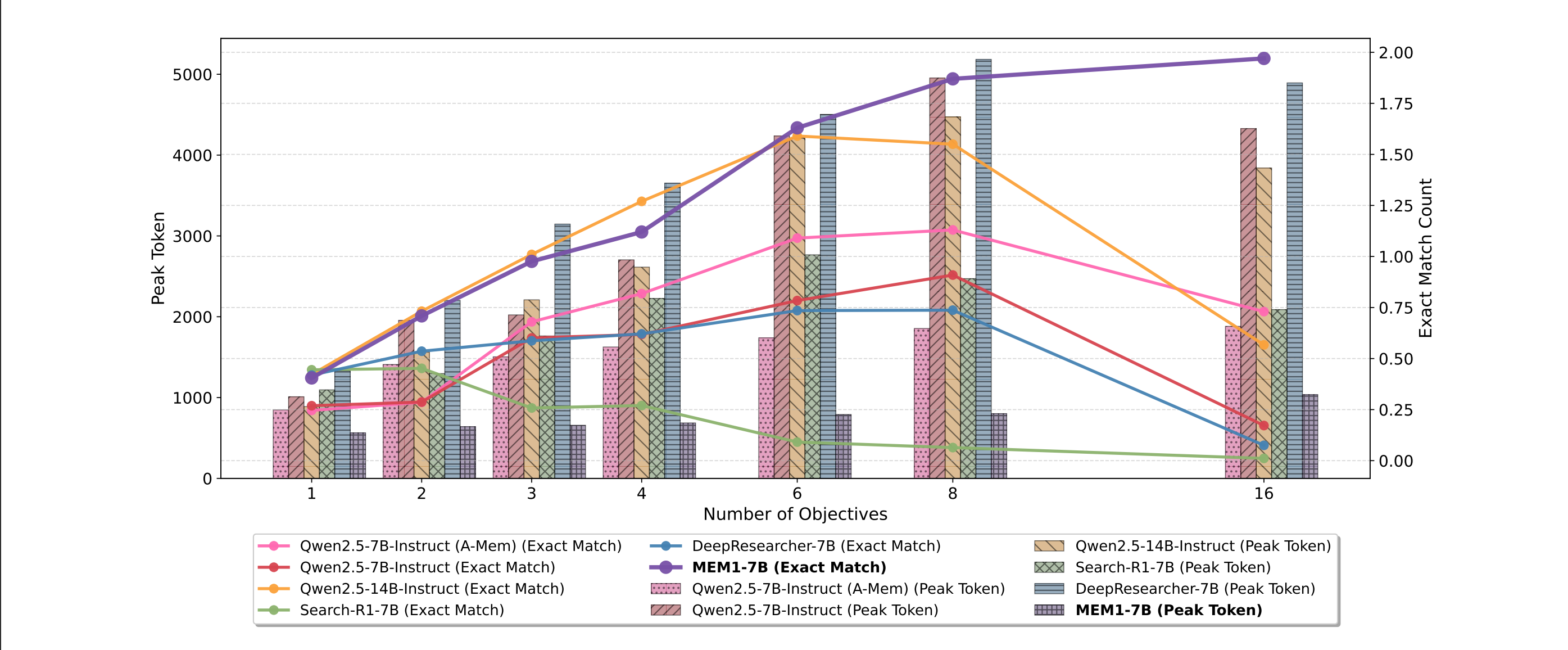
Caption: The red-colored values for 'Peak' and 'Time' for Search-R1 and DeepResearcher indicate that while these models might sometimes show seemingly 'lower' peak token usage or 'faster' inference times on highly complex tasks (like 8- and 16-objective), this is generally misleading. Their performance has severely degraded (as evidenced by their near-zero EM and F1 scores), meaning they are effectively failing at the task rather than genuinely achieving efficiency while maintaining accuracy. MEM1, on the other hand, achieves superior accuracy alongside competitive or better efficiency on these complex tasks.
As we can see from the table above, MEM1 is a competitive performer on all 2, 8, and 16 objective QA tasks, being one of the top performers in all of them and achieving high EM and F1 scores. This implies that MEM1 scales beautifully as task complexity grows.
In terms of Efficiency (Peak Token and Time), this is where it truly shines. MEM1-QA consistently maintains low peak token usage compared to other models. Even the Qwen2.5-7B-Inst (truncate) model, which tries to manage memory, still has higher peak token usage (8.28, 11.8, 13.3) than MEM1 for most tasks.
In terms of inference time, for 2-Objective, DeepResearcher is slightly faster. However, for 8-Objective and 16-Objective, MEM1-QA (8.68s and 8.70s, respectively) is significantly faster than most competitors, especially those that attempt to maintain higher accuracy, like Qwen2.5-7B-Inst (A-MEM). Search-R1 is faster for 8 and 16 objectives, but this comes at the cost of almost zero accuracy, so it's not a meaningful comparison.
Conclusion
Hence, overall, the paper presents a new way to think about memory management in agents for better long-horizon performance.